Read CamelQA's YC W24 launch story, originally shared on Hacker News.
Flaky UI tests suck. We want to create a solution where engineers don’t waste time maintaining fragile scripts.
camelQA uses a combination of accessibility element data along with an in-house custom vision-only RCNN object detection model paired with Google Siglip for UI element classification (see a sample output here - https://camelqa.com/blog/sole-ui-element-detector.png). This way we’re able to detect elements even if they do not have accessibility elements associated with them.
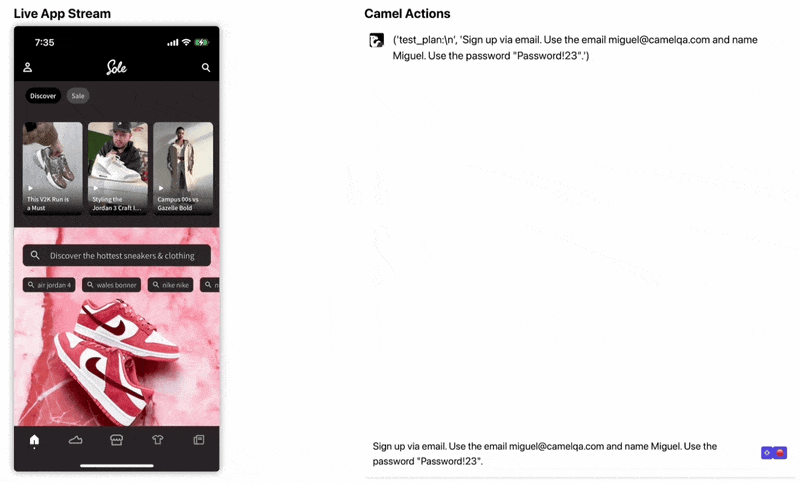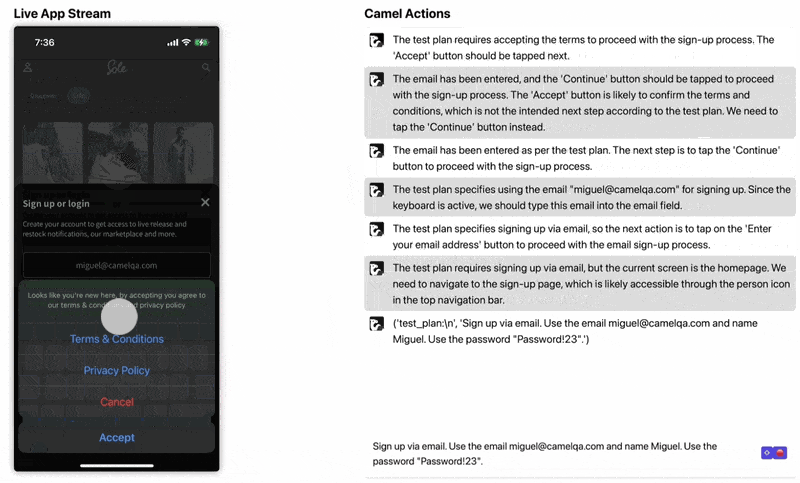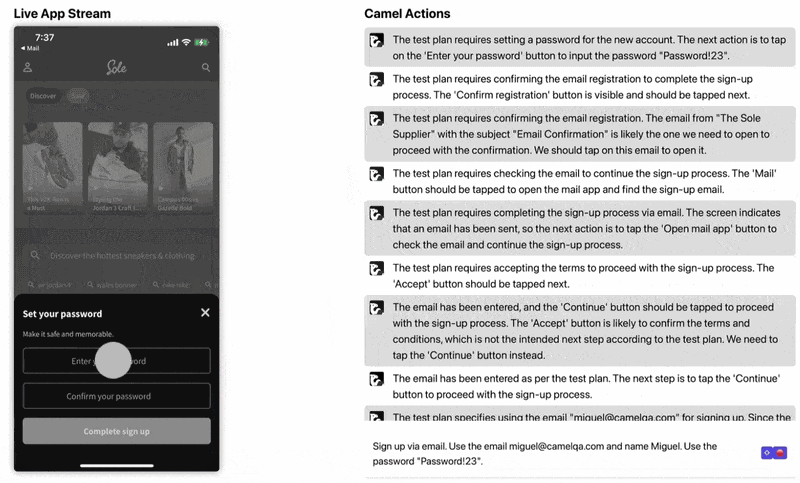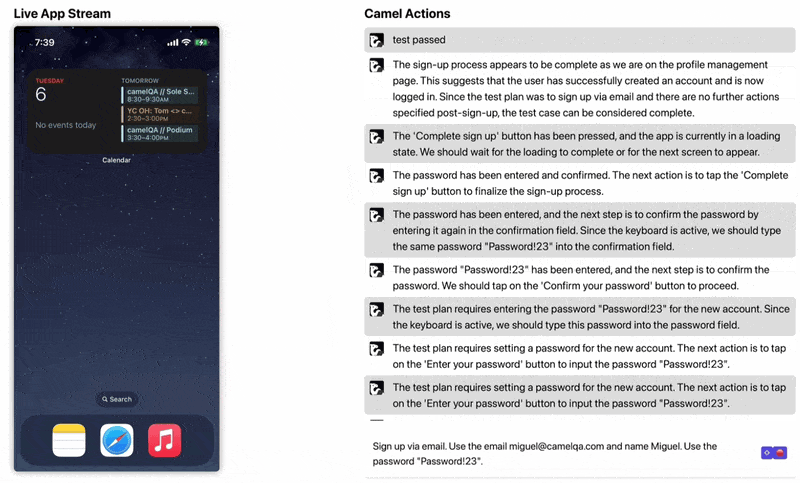
Under the hood the agent is using Appium to interface with the device. We use GPT-4V to reason at a high level and GPT-3.5 to execute the high-level actions. Check out a gif of our playground here (https://camelqa.com/blog/sole-signup.gif)
Since we’re vision based, we don’t need access to your source code and we work across all app types - SwiftUI and UIKit, React Native, Flutter.
We built a demo for HN where you can use our model to control Wikipedia on a simulated iPhone. Check that out here (https://demo.camelqa.com/). Try giving it a task like “Bookmark the wiki page for Ilya Sutskever“ or “Find San Francisco in the Places tab”. We only have 5 simulators running so there may be a wait. You get 5 minutes once you enter your first command.
If you want to see what our front end looks like, we made an account with some test runs. Use this login (Username: hackerNews Password: 1337hackerNews!) to view our sandboxed HN account (https://dash.camelqa.com/login).
Last year we left our corporate jobs to build in the AI space. It felt like we were endlessly testing our apps, even for minor updates, and we still shipped a bug that caused one of our apps to crash on subscribe (the app in question - https://apps.apple.com/us/app/tldr-ai-summarizer/id644930471...). That was the catalyst for camelQA.
We’re excited to hear what you all think!
 by Andrey
Azimov
by Andrey
Azimov
{kind=link}
{kind=link}